
从GPT-2到gpt-oss, 深度详解OpenAI开放模型的进化之路

从GPT-2到gpt-oss, 深度详解OpenAI开放模型的进化之路
更新时间: 浏览次数: 258
编译:Panda
众所周知,OpenAI 并不够 Open,不仅研究论文发得越来越少,开源模型也是千呼万唤始出来。其近日发布的两个 gpt-oss 开源模型已经吸引了无数关注,网上也已经出现了不少解读文章或视频。
近日,我们熟悉的 Sebastian Raschka 也发布了一篇深度技术博客,对 gpt-oss 进行了详细分析,并回顾了自 GPT-2 以来 AI 社区取得的进步;此外,他还将其与 Qwen 3 进行了比较。
博客标题:From GPT-2 to gpt-oss: Analyzing the Architectural Advances, And How They Stack Up Against Qwen3
博客地址:https://sebastianraschka.com/blog/2025/from-gpt-2-to-gpt-oss.html
以下为该博客文章的主要内容:
gpt-oss-120b 和 gpt-oss-20b 是自 2019 年 GPT-2 发布以来 OpenAI 发布的首批开放权重模型。得益于一些巧妙的优化,它们可以在本地运行。
我花了几天时间阅读代码和技术报告,总结出了其中最有趣的细节。
本文主要包括以下内容:
与 GPT-2 的模型架构比较
MXFP4 优化,使 gpt-oss 模型能够在单 GPU 上运行
宽度与深度的权衡(gpt-oss 与 Qwen3)
注意力偏差和 sinks
基准结果以及与 GPT-5 的比较
1、模型架构概述
在更详细地讨论架构之前,我们先大概了解一下这两个模型:gpt-oss-20b 和 gpt-oss-120b。
如果你对 LLM 架构有所了解,可能乍一看会觉得这两个 gpt-oss 并没有什么新颖或不寻常之处。
这并不奇怪,因为领先的 LLM 开发商倾向于使用相同的基础架构,然后进行一些较小的调整。这纯粹是我的猜测,但我认为这是因为:
这些实验室之间存在大量的人员流动。
我们仍然没有找到比 Transformer 架构更好的架构。尽管现在已经有了状态空间模型(SSM)和文本扩散模型,但据我所知,还没有人证明它们在这种规模下的性能可媲美 Transformer。
大部分改进可能来自数据和算法的调整,而非重大的架构变更。
话虽如此,它们的设计选择仍然有很多有趣的方面。其中一些在上图中有所展示(也有一些没有,但我们稍后也会讨论)。在本文的其余部分,我将重点介绍这些特性,并逐一将它们与其他架构进行比较。
这里简单说明一下,gpt-oss-20b 模型可以在配备了 16 GB RAM 的消费级 GPU 上运行。gpt-oss-120b 模型可在配备 80 GB RAM 或更高配置的单块 H100 处理器上运行。但后面还会提到一些重要的注意事项。
2、自 GPT-2 以来的变化
在比较 gpt-oss 和更新的架构之前,让我们先回到过去,将其与 GPT-2 对比一番(图 2),看看它到底取得了多大的进展。
图 2:gpt-oss-20b 与 GPT-2 XL 1.5B 的比较。
gpt-oss 和 GPT-2 都是基于 2017 年的论文《Attention Is All You Need》中提出的 Transformer 架构构建的仅解码器 LLM。
但多年时间已过,许多细节已经变化。
然而,这些变化并非 gpt-oss 独有。正如后面介绍的,它们也出现在许多其他 LLM 中。
2.1 移除 Dropout
2012 年提出的 Dropout 是一种传统的防止过拟合的技术,其实现方式是在训练过程中随机「丢弃」(即将其设置为零)一部分层激活值或注意力分数(图 3)。然而,Dropout 在现代 LLM 中很少使用,GPT-2 之后的大多数模型都已放弃这种技术。
我推测,GPT-2 之所以使用 Dropout,是因为它继承自原始的 Transformer 架构。研究者可能后面注意到,它并没有真正提升 LLM 的性能(我在小规模的 GPT-2 复现运行中也观察到了同样的情况)。这可能是因为 LLM 通常只在海量数据集上进行单轮训练,这明显不同于 Dropout 最初引入时针对的数百轮训练方案。因此,由于 LLM 在训练过程中每个 token 只被识别一次,因此过拟合的风险很小。
有趣的是,虽然 Dropout 在 LLM 架构设计中多年来一直被忽略,但我找到了一篇 2025 年的研究论文《Drop Dropout on Single-Epoch Language Model Pretraining》—— 其中包含小规模的 LLM 实验 (Pythia 1.4B),证实了 Dropout 在这些单轮训练方案中会导致下游性能下降。
2.2 RoPE 取代绝对位置嵌入
在基于 Transformer 的 LLM 中,由于注意力机制的存在,位置编码是必需的。默认情况下,注意力机制会将输入 token 视为无序的。在原始 GPT 架构中,绝对位置嵌入会通过为序列中的每个位置添加一个学习到的嵌入向量(图 4)来解决这个问题,然后将其添加到 token 嵌入中。
RoPE(旋转位置嵌入)则是一种不同的方法:它不是将位置信息添加为单独的嵌入,而是通过根据每个 token 的位置对查询和键向量执行旋转来编码位置。
RoPE 于 2021 年首次提出,并随着 2023 年原始 Llama 模型的发布而得到广泛采用,此后已成为现代 LLM 的主要组成部分。
2.3 Swish/SwiGLU 取代 GELU
早期的 GPT 架构使用 GELU。为什么现在的使用 Swish 而不是 GELU?
在我看来,Swish 的计算成本略低,这就是它的全部优势。在不同的论文中,两者的建模性能都可能更优。在我看来,这些细微的差异可能在标准误差范围内,实际结果会根据超参数敏感度而有所不同。
激活函数曾经是一个热门的争论话题,直到十多年前深度学习社区基本确定采用 ReLU 函数。此后,研究者提出并尝试了许多类似 ReLU 的变体,这些变体具有更平滑的曲线,而 GELU 和 Swish(图 5)是其中最受青睐的变体。
图 5:Swish 和 GELU 激活函数的比较,它们都是 ReLU 的更平滑版本。
早期的 GPT 架构使用 GELU,其定义为 0.5x * [1 + erf (x /sqrt (2))]。其中,erf(误差函数的缩写)是高斯积分,它使用高斯积分的多项式近似来计算,这使得它的计算成本比 Swish 中使用的 S 型函数(其中 Swish 只是 x * sigmoid (x))等更简单的函数更高。
实际上,Swish 的计算成本略低于 GELU,这可能就是它在大多数较新的模型中取代 GELU 的主要原因。
如今,Swish 已被应用于大多数架构。然而,GELU 并未被完全遗忘;例如,谷歌的 Gemma 模型仍然使用 GELU。
然而,更值得注意的是,前向模块(一个小型多层感知器)已被门控的「GLU」所取代,其中 GLU 代表门控线性单元,是在 2020 年的一篇论文中提出的。具体来说,2 个全连接层被 3 个全连接层所取代。
乍一看,GEGLU/SwiGLU 变体似乎比常规前向层更好,因为仅仅是因为增加了一层,参数就更多了。但这并非易事,因为在实践中,SwiGLU/GEGLU 中的 W 和 V 权重层通常被选择为传统前向层中 W_1 层大小的一半。
为了更好地说明这一点,来看看常规和 GLU 变体的具体代码实现:
图 7:常规前向模块(上)和 SwiGLU 变体(下)
因此,假设嵌入维度为 1024。在常规前向情况下,将会有:
fc1:1024 × 4096 = 4,194,304
fc2:1024 × 4096 = 4,194,304
也就是说,fc1 + fc2 = 8,388,608 个参数。
对于 GLU 变体,则有:
fc1:1024 × 1024 = 1,048,576
fc2:1024 × 1024 = 1,048,576
fc3:1024 × 1024 = 1,048,576
因此,总体而言,使用 GLU 变体可以减少参数数量,并且性能也更好。性能更佳的原因是这些 GLU 变体提供了额外的乘法交互,从而提高了表示能力(这与深度细长的神经网络比浅层宽广的神经网络表现更好的原因相同,前提是它们训练得当)。
2.4 混合专家取代单个前向模块
除了将前向模块升级为 SwiGLU 之外,gpt-oss 还将单个前向模块替换为了多个前向模块,每个 token 生成步骤仅使用一个子集。这种方法被称为混合专家模型 (MoE),如下图 8 所示。
图 8:前向模块被混合专家 (MoE) 取代。
因此,用多个前向模块替换单个前向模块(就像在 MoE 设置中所做的那样)会显著增加模型的总参数数量。然而,关键在于我们不会为每个 token 使用(「激活」)所有专家模型。相反,路由器只会为每个 token 选择一小部分专家模型。
由于每次只有少数专家模型处于活动状态,因此 MoE 通常被描述为稀疏模块,而密集模块则始终使用完整的参数集。然而,通过 MoE 形式积累的大量参数会增加 LLM 的容量,这意味着它在训练过程中会积累更多知识。同时,稀疏性可保证推理的高效性,因为我们不会同时使用所有参数。
(有趣的事实:在大多数 MoE 模型中,专家权重占模型总参数的 90% 以上。)
2.5 分组查询注意力取代多头注意力
近年来,分组查询注意力 (GQA) 兴起,成为了一种比多头注意力 (MHA) 计算效率和参数效率更高的替代方案。
在 MHA 中,每个注意力头都有自己的一组键和值。GQA 通过将多个注意力头分组以共享相同的键和值投影来减少内存占用。
例如,如图 9 所示,如果有 2 个键值组和 4 个注意力头,则注意力头 1 和 2 可能共享一组键和值,而注意力 3 和 4 则共享另一组键和值。这种分组会减少键和值的计算总量,从而降低内存占用并提高效率,而且根据消融研究,这不会显著影响建模性能。
图 9:MHA 与 GQA 的比较。此处,分组大小为 2,其中键值对在 2 个查询之间共享。
因此,GQA 的核心思想是通过在多个查询头之间共享键和值头来减少键和值头的数量。这可 (1) 降低模型的参数数量,(2) 减少推理过程中键和值张量的内存带宽占用,因为需要从键值缓存中存储和检索的键和值更少。
虽然 GQA 主要是为了提高 MHA 的计算效率,但一些消融研究(例如原始 GQA 论文和 Llama 2 论文中的研究)表明,它在 LLM 建模性能方面与标准 MHA 相当。
2.6 滑动窗口注意力
滑动窗口注意力(下图 10)最早在 LongFormer 论文(2020 年)中提出,后来由 Mistral 推广。有趣的是,gpt-oss 每隔一层就应用一次它。你可以将其视为多头注意力(在本例中为分组查询注意力 (GQA))的一种变体,其中注意力上下文被限制在较小的窗口中,从而可同时降低内存使用量和计算成本。
图 10:常规注意力(左)与滑动窗口注意力(右)的比较。
具体来说,gpt-oss 会交替关注完整上下文的 GQA 层和滑动窗口限制为 128 个 token 的 GQA 层。
实际上,Gemma 2 (2024) 也使用了类似的 1:1 比例。今年早些时候发布的 Gemma 3 则更进一步,改为 5:1 的比例,这意味着每五个滑动窗口(局部)注意力层只有一个完整的注意力层。
根据 Gemma 的消融研究,滑动窗口注意力对建模性能的影响微乎其微,如下图所示。需要注意的是,Gemma 2 中的窗口大小为 4096 个 token,而 Gemma 3 将其减少到 1024 个 token。在 gpt-oss 中,窗口只有 128 个 token,非常小。
另外,有趣的是,OpenAI 的官方文章指出,滑动窗口注意力显然已在 GPT-3 中使用:「这些模型使用了交替的密集和局部带状稀疏注意力模式,类似于 GPT-3」
我回顾了 GPT-3 的原始论文,那里确实提到了这一点:「我们使用了与 GPT-2 相同的模型和架构,包括其中描述的修改后的初始化、预归一化和可逆 token 化,不同之处在于,我们在 Transformer 的各层中使用交替的密集和局部带状稀疏注意力模式,类似于 Sparse Transformer。」
2.7 RMSNorm 替换 LayerNorm
最后一个不同于 GPT-2 的小调整是用 RMSNorm (2019) 替换 LayerNorm (2016),这是近年来的一个常见趋势。
类似于用 Swish 和 SwiGLU 替换 GELU,RMSNorm 也是合理的效率小改进之一。 RMSNorm 与 LayerNorm 类似,其目的都是对层激活进行归一化,如下图 11 所示。
你可能还记得,不久前,BatchNorm 还是这项任务的首选。但后来它逐渐失宠,主要是因为它难以高效并行化(由于均值和方差的批次统计数据),并且在小批量下表现不佳。
图 11:LayerNorm(左)和 RMSNorm(右)在小型线性层中的比较。
如上图 11 所示,LayerNorm 和 RMSNorm 都会将层输出缩放到合理的范围内。
LayerNorm 的做法是减去均值并除以标准差,使得层输出具有零均值和单位方差(方差为 1,标准差为 1)。
RMSNorm 则是将输入除以均方根。这不会强制要求均值和方差为零,但均值和方差应处于合理范围内:均值在 -1 到 1 之间,方差在 0 到 1 之间。在图 11 所示的特定示例中,均值为 0.77,方差为 0.41。
LayerNorm 和 RMNSorm 都能稳定激活尺度并改善优化效果,但 RMNSorm 通常更适合大规模 LLM,因为它的计算成本更低。与 LayerNorm 不同,RMNSorm 没有偏差(平移)项,并将昂贵的均值和方差计算简化为一次均方根运算。这将跨特征约简的次数从两次减少到一次,从而降低 GPU 的通信开销并提高训练效率。
2.8 GPT-2 的遗产
我仍然认为,在学习 LLM 时,GPT-2 是一个优秀的入门架构。它足够简单易懂,不会迷失在层层优化技巧中,但又足够复杂,能够让你扎实掌握现代 Transformer 模型的工作原理。
从 GPT-2 开始,你可以专注于基础知识(注意力、位置嵌入、规范化和整体训练流程),而不会被新架构中的额外功能和调整所淹没。
事实上,我认为在尝试叠加新的变化之前,先花时间了解甚至实现 GPT-2 是值得的。你不仅能更容易地理解这些变化,而且你可能会更加欣赏它们,因为你将更好地理解它们试图解决的局限性或问题。
例如,我最近从我的 GPT-2 代码入手,从零开始实现了 Qwen3 架构,它与 gpt-oss 非常相似,这就引出了下一个话题:将 gpt-oss 与更新的架构进行比较。
从头开始实现 Qwen3:https://github.com/rasbt/LLMs-from-scratch/tree/main/ch05/11_qwen3
3、比较 gpt-oss 与最新架构 (Qwen3)
现在我们已经了解了从 GPT-2 到 gpt-oss 的演变过程,接下来我们将 gpt-oss 与更新的架构 Qwen3 进行比较,后者于三个月前(2025 年 5 月)发布。
我之所以选择 Qwen3,是因为截至撰写本文时,它是顶级的开放权重模型之一。此外,Qwen3 也是 MoE 模型,由于其可训练参数的总体规模相对相似,几乎可以直接与 gpt-oss 相比。
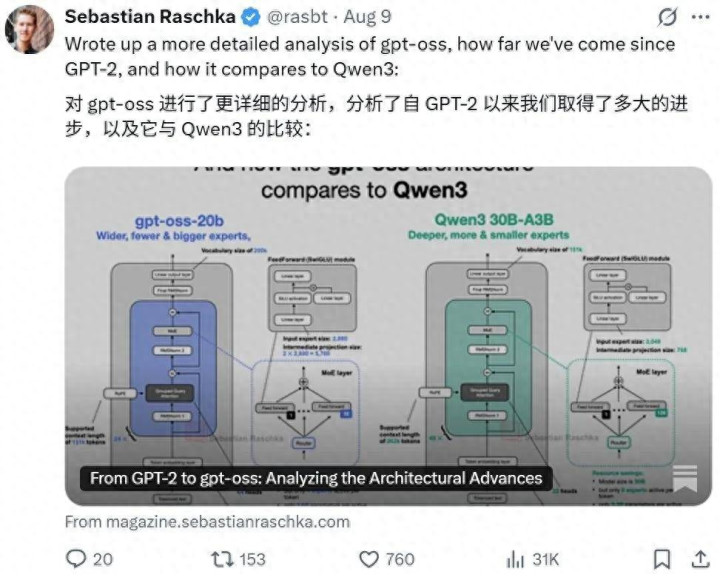
下图对比了 gpt-oss-20B 与大小相当的 Qwen3 模型。
图 13:大小相当的 gpt-oss 和 Qwen3 模型。
可以看到,gpt-oss 20B 和 Qwen3 30B-A3B 在架构组件上非常相似。除了尺寸之外,主要区别在于 gpt-oss 采用了滑动窗口注意力,而 Qwen3 则没有。
我们将在以下小节中逐一介绍值得注意的细节。
3.1 宽度与深度
仔细观察这两个模型,我们会发现 Qwen3 的架构更深,它有 48 个 Transformer 模块,而不是 24 个。
另一方面,gpt-oss 的架构更宽:
嵌入维度为 2880,而非 2048
中间的专家(前向)投影维度也为 2880,而非 768
还值得注意的是,gpt-oss 使用了两倍的注意力头,但这并不会直接增加模型的宽度。宽度由嵌入维度决定。
在参数数量固定的情况下,哪种方法更有优势?根据经验,更深的模型更灵活,但由于梯度爆炸和梯度消失(RMSNorm 和 shortcut 连接旨在缓解这些问题)导致的不稳定性问题,训练起来可能更困难。
更宽的架构具有推理速度更快的优势(每秒 token 吞吐量更高),这是因为并行化程度更高,但内存成本也更高。
就建模性能而言,遗憾的是,据我所知,除了 Gemma 2 论文(表 9)中的一项消融研究(ablation study)之外,目前尚无很好的同类比较(在参数大小和数据集保持不变的情况下)。该研究发现,对于 9B 参数架构,较宽的设置略优于较深的设置。在 4 个基准测试中,较宽的模型平均得分为 52.0,而较深的模型平均得分为 50.8。
3.2 少量大型专家 vs. 大量小型专家
如上图 14 所示,值得注意的是,gpt-oss 的专家数量出奇地少(32 个而不是 128 个),并且每个 token 仅使用 4 个而不是 8 个活跃专家。然而,每个专家的数量都比 Qwen3 中的专家数量要多得多。
这很有意思,因为最近的趋势和发展表明,更多、更小的模型是有益的。在总参数大小不变的情况下,这种变化在来自 DeepSeekMoE 论文的下图中得到了很好的展示。
图 15:来自《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》的图片,https://arxiv.org/abs/2401.06066
值得注意的是,与 DeepSeek 的模型不同,gpt-oss 和 Qwen3 都没有使用共享专家。
公平地说,gpt-oss 中专家数量较少可能是 20B 规模的副作用。查看下面的 120B 模式,它们确实增加了专家(和 Transformer 模块)的数量,同时保持其他所有参数不变,如下图所示。
图 16:两个 gpt-oss 架构比较,其中更大的 120B 模型仅扩展了 Transformer 模块和专家的数量。
20B 和 120B 模型如此相似的一个无聊解释可能是因为 120B 模型是主要关注点。而创建较小模型最简单的方法是使其更短一些(减少 Transformer 模块)并减少专家数量,因为大多数参数都存储在专家数量中。然而,有人可能会猜测他们是否先训练 120B 模型,然后砍掉一些 Transformer 模块和专家数量用于继续预训练(而不是从随机权重开始)。
无论如何,这是因为只缩放这两者(Transformer 模块和专家数量)的情况并不常见。例如,在查看多种尺寸的 Qwen3 MoE 模型(下图 17)时,它们在更多方面彼此之间进行了更均衡的缩放。
图 17:各种 Qwen3 模型的架构差异。
3.3 注意力偏差和 sinks
gpt-oss 和 Qwen3 都使用分组查询注意力。主要区别在于,如前所述,gpt-oss 通过在每个第二层中滑动窗口注意力来限制上下文大小。
然而,有一个有趣的细节引起了我的注意。gpt-oss 似乎为注意力权重使用了偏差单元(bias units),如下图所示。
图 18:gpt-oss 模型在注意力层中使用了偏差单元。
自 GPT-2 时代以来,我就没见过这些偏差单元被使用,它们通常被认为是多余的。事实上,我发现了一篇最近的论文,从数学上证明了至少对于键变换 (k_proj) 来说,情况确实如此。此外,实证结果表明,使用和不使用偏差单元之间几乎没有差异(见下图 19)。
图 19:来自 https://arxiv.org/pdf/2302.08626 的表格,显示了使用和不使用偏差单元从头开始训练模型时的平均测试损失。
你可能注意到的另一个细节是图 18 代码截图中 sinks(sinks)的定义。在一般模型中,注意力 sinks 是放置在序列开头的特殊「始终关注」token,用于稳定注意力,这在长上下文场景中尤其有用。也就是说,如果上下文变得很长,开头这个特殊的、被关注的 token 仍然会被关注,并且它可以学习存储一些关于整个序列的普遍有用的信息。
在 gpt-oss 实现中,注意力 sinks 并非输入序列中的实际 token。相反,它们是学习到的每人偏差逻辑单元 (per-headbias logits),并附加到注意力分数中(图 20)。其目标与上述注意力 sinks 相同,但不修改 token 化的输入。
图 20:gpt-oss 中注意力 sinks 的使用
3.4 许可证
最后,与 Qwen3 类似,gpt-oss 模型采用了 Apache 2.0 开源许可证,这非常棒(这也是我自己的开源项目所偏好的许可证)。这意味着这些模型可以不受限制地蒸馏成其他模型或用于商业产品。
开放权重 LLM vs 开源 LLM:这种区别多年来一直存在争议,但值得澄清以避免混淆。一些模型开发者只发布模型权重和推理代码(例如 Llama、Gemma 和 gpt-oss),而另一些模型开发商则会将所有东西都开源,包括训练代码、数据集和权重。(例如 OLMo)
按照更严格的定义,gpt-oss 是一个开放权重模型(就像 Qwen3 一样),因为它包含权重和推理代码,但不包含训练代码或数据集。然而,业界对这一术语的使用并不一致。
我曾经以为「gpt-oss」中的「oss」表示开源软件(open source software);然而,令我惊讶的是,OpenAI 在其官方公告文章中明确地将 gpt-oss 描述为开放权重模型。
4、其他有趣细节
虽然前面几节描述了该架构自 GPT-2 以来的演变,并讨论了它与 Qwen3(以及大多数其他近期模型)的相似之处,但还有一些值得注意的细节尚未提及。
这些要点不适合放在前面几节,但仍然值得一提。
4.1 训练概况
遗憾的是,关于 gpt-oss 的训练集大小和算法的信息并不多,但我从其模型卡 (1) 和宣布文章 (2) 中找到了一些有趣的拼图碎片:
由此,我们知道 gpt-oss 模型是推理模型。训练计算量是 210 万个 H100 GPU 小时数,与规模约 5.6 倍的 DeepSeek V3 模型所需的 278.8 万个 H800 GPU 小时数的训练计算量大致相当。遗憾的是,目前尚无关于 Qwen3 训练时间的信息。
有趣的是,gpt-oss 的训练时间估算包含了用于指令遵循的监督学习和用于推理的强化学习,而 DeepSeek V3 只是一个预训练的基础模型,DeepSeek R1 是在此基础上单独训练的。
4.2 推理工作
如上一节所述,gpt-oss 模型是推理模型。然而,特别有趣的是,它们的训练方式使得用户可以通过推理时间缩放轻松控制推理程度。
具体来说,gpt-oss 模型可以接收「推理工作量:低 / 中 / 高」指令作为其系统提示词的一部分,这可直接影响响应长度和准确率,如图 21 所示。
图 21:不同推理工作量下 gpt-oss 模型的响应长度和质量
这种可调整性非常有用,因为它使我们能够平衡成本、计算量和准确率。例如,如果任务很简单,例如回答一个简单的知识问题或修复一个小拼写错误,我们可以跳过扩展推理。这能节省时间和资源,同时避免不必要的冗长响应和冗长的推理痕迹。
与 Qwen3 或 OLMo 不同,OpenAI 没有发布强化学习训练之前的基础模型,这多少有些遗憾。基础模型对于研究推理方法的研究者来说是极其宝贵的起点(这也是我目前喜欢使用 Qwen3 Base 的原因之一)。我猜测,OpenAI 的决定更多是出于行业和生产用例的考虑,而非研究方面的考虑。
请注意,原始 Qwen3 模型也有一个用于启用 / 禁用思考(推理)模式的开关(通过在 tokenizer 中设置 enable_thinking=True/False 来启用 / 禁用推理行为)。然而,Qwen3 团队在过去几周更新了他们的模型,并从混合模型转向了专用的 Instruct/Thinking/Coder 变体。
原因是混合模式下的模型性能低于单个模型:「在与社区讨论并反思此事后,我们决定放弃混合思考模式。现在我们将分别训练 Instruct 和 Thinking 模型,以实现最佳质量。」
4.3 MXFP4 优化:一个细小却重要的细节
一个有趣的惊喜是,OpenAI 还发布了为 MoE 专家采用了 MXFP4 量化方案的 gpt-oss 模型。
量化格式曾经是一个小众话题,主要与移动或嵌入式 AI 相关,但随着模型规模的扩大,这种情况发生了变化。在这种情况下,MXFP4 优化能让模型在单台 GPU 设备上运行。
实际效果如下:
大型模型(例如 120B)可安装在单台 80GB H100 或更新的 GPU 上。虽然不是消费级硬件,但租用一台单 H100 的机器比租用多台 H100 的机器便宜得多。此外,我们不必担心在 GPU 之间分配模型并增加通信开销。 AMD MI300X 显卡从第一天起就支持,真是太好了!
较小的 20B 模型甚至可以使用 16 GB 显存;需要注意的是,它必须是 RTX 50 系列或更新的 GPU 才能支持 MXFP4。
请注意,这些模型也可以在较旧的硬件上运行,但不支持 MXFP4,因此会消耗更多内存。如果没有 MXFP4 优化,bfloat16 模型将消耗更多内存,例如 48 GB(gpt-oss-20b)和 240 GB(gpt-oss-120b)。
顺便说一句,我可以在 Mac Mini 上使用 ollama 轻松运行 gpt-oss-20b 模型。它占用大约 13.5 GB 的内存。嗯,很合理。
4.4 基准成绩
这些模型还比较新,还没有多少可靠的独立基准测试结果。比如 LM Arena 排行榜上,gpt-oss 尚未上榜。因此,根据 LM Arena 用户的数据,Qwen3-Instruct 目前仍然引领开放权重模型(图 22)。
图 22:LM Arena 排行榜当前视图(截至 2025 年 8 月 12 日)
只看 gpt-oss 发布博文中提供的推理基准测试,我们可以看到 gpt-oss 模型与 OpenAI 的专有模型以及 Qwen3 的性能相当(图 23)。
图 23:主要基准测试图表来自官方 gpt-oss 官方公告。「no tools」的 gpt-oss-120b 数据取自官方模型卡,Qwen3 数据取自官方 Qwen3 代码库。
然而,需要注意的是,gpt-oss-120b 的大小几乎只有 Qwen3 A235B-A22B-Thinking-2507 模型的一半,而且可以在单台 GPU 上运行。
然而,基准测试性能并不总是反映实际可用性。在过去几天有限的使用中,我发现 gpt-oss 相当强大。不过,正如其他人所观察到的,它似乎确实有相对较高的幻觉倾向(这一点在其模型卡中也有提到)。
这可能源于它在训练过程中过于注重数学、谜题和代码等推理任务,这可能导致它「遗忘了一些常识」。不过,由于 gpt-oss 在设计时就考虑到了工具的使用,因此随着时间的推移,这一限制可能会逐渐减弱。开源 LLM 中的工具集成仍处于早期阶段,但随着它的成熟,我预计我们会越来越多地让模型在回答事实或基于知识的查询时参考外部资源(例如搜索引擎)。
届时,更明智的做法是优先考虑推理能力而不是记忆能力。这很像人类在学校(或生活中)的学习,解决问题的能力往往比记忆事实更重要。
5、gpt-oss 和 GPT-5
OpenAI 度过了忙碌的一周,在 gpt-oss 发布后不久就发布了备受期待的 GPT-5 模型。GPT-5 的发布非常有趣。如果说有什么要说的,那就是我真的很惊讶,他们的开源模型在基准性能方面与他们最好的产品相比竟也如此出色(图 24)。
图 24:主要基准图表来自 GPT-5 官方公告。gpt-oss 数据取自官方模型卡和公告,Qwen3 数据取自官方 Qwen3-Coder 代码库。
总而言之,尽管有些人认为该版本被过度炒作,但我很高兴我们拥有了一套真正强大的开放权重模型,它们与最好的专有模型并无太大差距。
当然,基准测试通常不能准确反映实际使用情况,而且由于使用情况有限,现在下结论还为时过早。但我认为,对于喜欢使用开放权重和本地(或私有托管)模型的人来说,这是件好事。
寒武纪成交额超100亿元,现跌8%每经AI快讯,9月4日,截至发稿时,寒武纪-U成交额超100亿元,现跌8%。海量资讯、精准解读,尽在新浪财经APP
- 微信好友
- 朋友圈
- QQ好友
-
分享海报


- 复制链接
- QQ空间
- 新浪微博
- 狐友


推荐阅读
退租辱骂致死案二审
 746
746

以没收巴勒斯坦土地
79

花间一梦
2025-09-05 08:25:01
553
553

地铁看书遇北大博导
344

退租辱骂致死案二审
26

杭州雨后树上挂满虫
735

退租辱骂致死案二审
77

李雪琴同届考生发文
299

凯美瑞只卖12万了
19

复读1年高考涨380分
109
